
Omar Gadir, Ph. D., Founder/CEO.
Introduction
Despite impressive innovations in pharmaceutical technologies, companies are not producing drugs any faster than before. PricewaterhouseCoopers: reported that pharma’s output has flatlined for the past decade, which is indicative of poor scientific productivity and its core problem is lack of innovation in making effective new therapies for the world’s unmet medical needs. Some attribute lack of innovation to the reliance of pharma companies on manual procedures and the poor utilization of their data. Like other industries, pharma should start using data analytics to improve all aspects of their business in particular R&D. Here we will cover effective means to apply data analytics to pharma R&D.
Sources of Pharma Data
Pharma is a data intensive industry and there are many sources for its data. The sources are: scientific journals and other publications, Electronic Medical Records, genomic, screening data, clinical trial data, patents, FDA data and data generated within an organization such as documents, reports and results of lab work.
This article is concerned with analytics of data related to publications, patents and internal data generated within an organization. The end results of almost all pharma scientific experiments are publications. Patents provide the latest advances in therapeutics. Combining those two with internal data provides enormous source of information, if fully utilized should expedite R&D and reduce costs.
Types of Pharma Data
There are two types of pharma data formats: structured and unstructured. Structured data refers to data in tabular format (databases, CSV, excel and JSON ). Traditionally, CSV, excel and JSON are considered unstructured. However, because intrinsically they have tabular format, some consider them structured.
It is easy to extract information from structured data and process it. On the other hand unstructured data is very difficult to process. It constitutes more than 80% of enterprise data and has hundreds formats, such as PDF, PPT, video, images, custom and industry formats, data generated in labs, emails, etc. Except for PDF and textual data, unstructured data is very difficult to parse and extract intelligence from. For these reason it has been ignored, although it is much bigger than structured data.
Pharma Data Complexity
Pharma data is extremely complex. In addition to its complexity as unstructured data, other factors make it difficult to deal with. Those factors are:

- Many biological processes are not understood.
- Many processes in the life sciences are extremely entangled, with multiple variables operating at the same time to produce different, unintended or unknown results.
- Ambiguities regarding gene/protein names are a major problem in the literature and it is even worse in the sequence databases. For instance, the breast cancer protein BRCA2 has 12 aliases: BRCA2, BRCC2, BROVCA2, FACD, FAD, etc. To add to the complexity, the tumor protein (p53) has 7 aliases and interacts with the above breast cancer protein in addition to more than 100 other proteins.
- Many acronyms that change over time.
Current Data Access Tools Are Deficient
To access published data pharma companies use search engines provided by PubMed, PubChem, Thompson Reuters and others. Unfortunately, the search engines implementations filter the raw data and hide valuable insights.
Fig. 1 shows how data is accessed. At the bottom are the sources of pharma data. On top of that are the data formats that consists of structured and unstructured data. It is easy to extract insights from structured data. As for the unstructured data it is difficult to parse and extract information from it, except for PDF and textual data. The other hundreds unstructured data are ignored.
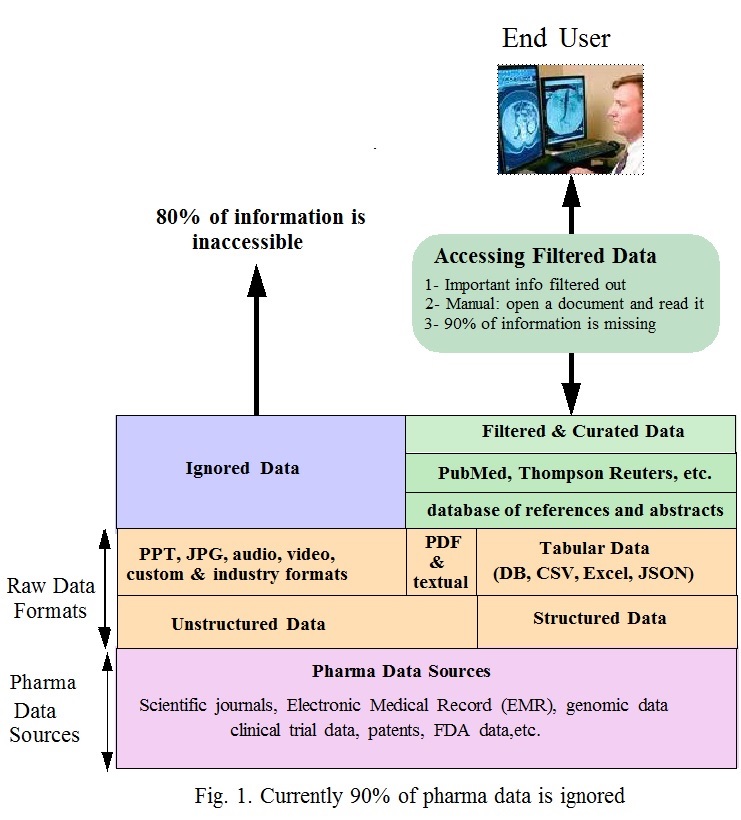
On the right side of the diagram, search engines provided by PubMed, PubChem, Thompson Reuters and others use databases of references and abstracts to access the structured data (tabular data), textual and PDF files.
This approach has the following serious drawbacks:
- Data selection and indexing is flawed: accessible documents are selected based on bibliographic information, limited keywords and/or specific terms. Abstracts of selected documents are indexed for search. Abstracts include minimal information about documents. Both the selection criteria and indexing of abstracts filter out many relevant documents. Indexing the full content is the appropriate solution. This what Google does.
- Using Curated data: In some cases curators map information from different sources and make them accessible by including them in databases. This enables researchers to study related items, for example, chemical structures, assay results and protein targets. Currently curated databases exist for a small number of applications. The process of creating them is manual and is time consuming. Many curated databases miss a sizable amount of information. Being a manual process, it is very difficult to updated curated data or correct errors.
- Delay in including new data: Voluminous new pharma data is generated everyday and new names and acronyms are created. Because of dependency on manual processes, to include new data into search engines and curated databases takes between 6 to 12 months. Pharma experts using the data may never know to what extent the search engines and curated databases are up to date.
To decide whether a selected document includes relevant information, the user has to manually open and read it. Out of hundreds of documents he/she can only cover a few. There is no guarantee the information extracted is optimal or correct.
Another problem is that Pharma search engines and curated databases cover a limited number of aliases given to the same biological entity. For instance, searching PubMed for the 12 aliases of BRCA2 produces inconsistent results. In 3 cases (BROVCA2, GLM3, PNCA2) PubMed could not find any match. For “breast cancer 2”, it found 366 documents and for the rest it found between 2189 and 1333 documents
New Products Do Not Solve The Problem
New data analysis products are complex and require hiring data engineers and/or data scientists. Data scientists are hard-to-find because of the multiple skills requirements. In addition to statistics, math and machine learning, they need to know programming languages, data engineering, databases and SQL, data mining and have a good understanding of the domain being analyzed. This constitutes 8 skill sets.
When data scientists try to perform data analysis, they face big challenges. In most cases they lack domain knowledge about the data they are trying to extract and analyze. Their knowledge of pharma R&D data is close to nothing. Only pharma domain experts have that knowledge. They acquire the knowledge after years of education and training in biomedical sciences. They know the intricacies of the data, how it is generated, the highly specialized biological, medical, and biochemical terms and the complex relationship between different data sets. They are the only experts who can extract insights about the processes that lead to disease, drug target identification, protein-protein interactions, DNA-protein interactions, side effects, toxicity, etc.
Trying to transfer knowledge from a pharma expert to a data scientist to enable them to perform R&D data analysis is a waste of time and effort. Another added difficulty is rapid evolution of the pharma domain knowledge. The best solution is to empower pharma domain experts by enabling them to perform analysis themselves.
In many cases empowered domain experts need data scientists as spot problem solvers addressing issues that may result in modifying, optimizing, or adding new analytics and machine learning algorithms. Once this is done domain experts can transparently access the updated algorithms via self-service. In this paradigm data analysis is merely a tool made available to pharma domain experts.
Empowering Pharma Domain Experts
To get effective intelligence, domain experts should be empowered to be able to interact directly with the raw data, extract information and perform analysis without help from data scientists and data engineers. Interacting directly with raw data removes dependency on deficient data access tools and eliminates limitations of curated data.
Raw data need to be preprocessed before information could be extracted from it. The preprocessing involves advanced parsing, indexing, data tagging and transformation. The transformation present the data in a format that enable domain experts to extract information without the need to know programming languages, data engineering, databases and SQL and data mining. This eliminates 4 out of the 8 skills of data scientists. A fifth skill, the domain expertise is owned by pharma domain experts. This reduces the skill set requirement for a data scientist to three: statistics, math and machine learning. It is much easier to find a data scientist with three skills set than eight.
Fig.2 shows how all data is made available to domain experts. In Fig. 1 the layers: “Database of references and abstracts”, “PubMed, Thompson Reuters, etc.” and “Filtered & Curated Data” are replaced in Fig. 2 by the “preprocessing layer” . The preprocessing includes: parsing, indexing and data transformation. This ensures that no document is excluded and eliminates the limitation of current data access methods. The preprocessing is executed automatically during data ingestion. On top of this is advanced analytics and machine learning layer. This layer includes self-service analytics and machine learning algorithms.
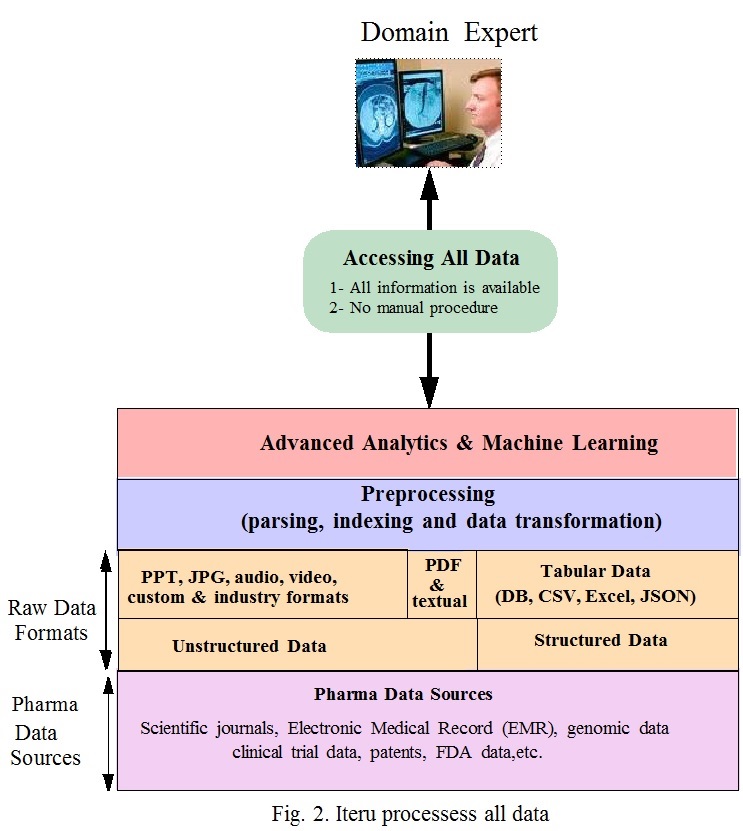
This way pharma domain experts are empowered to access the data and extract meaningful insights. Results are obtained in a few seconds. Because of the entanglement in pharma data and its complexity, each domain expert has a different approach to analyze and solve a problem. Increasing the number of employees performing data analysis increases the odds of obtaining solutions to difficult pharma R&D problems, enabling pharma companies to innovate and make effective new therapies.
Iteru Solution
Empowering domain experts to perform analytics is one of the main objectives of the startup, Iteru Systems. The solutions suggested in this article are the main features of its product. The product provides both preprocessing of data and the self-service analytics. As a result the role of a data scientist, with the limited skill sets of statistics, math and machine learning, becomes spot problem solver needed to enhance the self-service algorithms.