Iteru’s provides an end-to-end product for data analysis. It has been designed such that it can also be used with existing machine learning, analytics and virtualization products.
 In this blog we will focus on how Iteru helps customers to implement Machine Learning (ML). Some of the prerequisites for accurate ML are: understanding input data, its cleanliness and that it is in a format suitable for processing.
In this blog we will focus on how Iteru helps customers to implement Machine Learning (ML). Some of the prerequisites for accurate ML are: understanding input data, its cleanliness and that it is in a format suitable for processing.
In this respect, Iteru provides the following tools that enables a customer to:
- Understanding unstructured data:
- Use taxonomy classification to extract required documents. This ensures only data related to the subject matter of the analysis is extracted.
- Data cleansing.
- Transform data into a format amenable for processing by existing products.
The Hype Of Machine Learning
Machine learning is a branch of computer science that evolved from the study of pattern recognition and computational learning theory in artificial intelligence. It explores the study and construction of algorithms that can learn from and make predictions on data.
During the last few years there has been a big hype about machine learning as the ultimate solution that produces good results regardless of the data and the conditions under which algorithms are  executed. It is true that under certain conditions, machine learning can provide solutions by finding patterns and insights that were previously hidden. But that doesn’t mean any problem could be solved by simply feed messy data into a system, and expect viable results. The hype is driving people to invest time and money trying to find unattainable solutions. Guidelines that lead to successful implementation of machine learning are ignored. The outcome is too much time, money and other resources were spent trying to build unsuccessful products.
executed. It is true that under certain conditions, machine learning can provide solutions by finding patterns and insights that were previously hidden. But that doesn’t mean any problem could be solved by simply feed messy data into a system, and expect viable results. The hype is driving people to invest time and money trying to find unattainable solutions. Guidelines that lead to successful implementation of machine learning are ignored. The outcome is too much time, money and other resources were spent trying to build unsuccessful products.
Machine Learning Requirements
Results obtained by machine learning depend on the following:
- The quality of data: the messier the data the less accurate the results. The major stumbling block for many enterprises is the quality of the data.
- Problem should be well defined: machine learning can not provide general solutions.
- There is a tradeoff: more data leads to more accurate results, but more data means more computational requirements that could be beyond existing computing power.
- Continuous evaluation of the accuracy of the results. In self-driven cars, it easy to evaluate the accuracy by testing it in a road. But in many cases, for instance, in data mining, accuracy of the results is not straightforward.
- In cases where data changes, there is need to adapt the algorithms or adopt a new set of algorithms to get accurate results.
- Do not ask the computer to do something beyond its ability.
Some people who do not have experience in machine learning assume that human perception is similar to machine perception and can give similar results. That is not true. Humans excel in Gestalt tasks, in which the whole has a reality of its own, independent of the parts. For example, humans are very good at recognizing shapes and texture independently from their position, color, and orientation. As for computers, there is no general solution to this problem. On the other hand, computers can perform many tasks faster and more accurately than human. Algorithms can be used to automate mechanical functionality in real-time in a factory, airplane or car. Also, computers are good at discovering subtle correlations in data sets.
Why Google Flu Trends (GFT) Faltered?
In 2014, the journal Nature (SCIENCE VOL 343, 14 MARCH 2014), reported that GFT was predicting more than double the proportion of doctor visits for influenza-like illness (ILI) than the Centers for Disease Control and Prevention (CDC), which bases its estimates on surveillance reports from laboratories across the United States. This happened despite the fact that GFT was built to predict CDC reports. The Journal raised the question, “Given that GFT is often held up as an exemplary use of big data, what lessons can we draw from this error?”
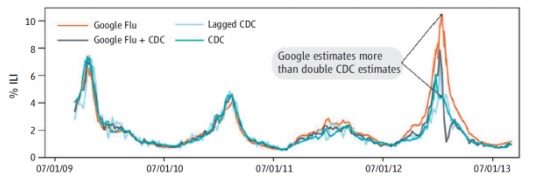 According to Nature, one major contributing cause of the failures of GFT may have been that the Google search engine itself constantly changes, such that patterns in data collected at one time do not necessarily apply to data collected at another time. Collections of big data that rely on web hits often merge data that was collected in different ways and with different purposes, sometimes to ill effect. It can be risky to draw conclusions from data sets of this kind.
According to Nature, one major contributing cause of the failures of GFT may have been that the Google search engine itself constantly changes, such that patterns in data collected at one time do not necessarily apply to data collected at another time. Collections of big data that rely on web hits often merge data that was collected in different ways and with different purposes, sometimes to ill effect. It can be risky to draw conclusions from data sets of this kind.
Iteru: First Understand Data And Cleanse It
One of the main stumbling block for adopting third party ML tools is understanding data and ensure its quality. In many cases, a customer may not know what data exists in a company repositories, as according to some estimates 80% of unstructured data is not accessible. In other words a customer has not even looked at it.
Iteru’s product accesses all the unstructured data making it available for ML. A customer can use interactive classification tools to interrogate the data, understanding it, extract relevant data, cleanse it and transform it in a format suitable for ML. This results in clean data and great data reduction. Clean data leads to accurate results and data reduction results in faster analysis and less computational power. Iteru ensures that ML problems like GFT will not occur when dealing with enterprise data.