AI Hype And Reality
Artificial intelligence, Deep Learning, Machine Learning and cognitive computing are the buzzwords
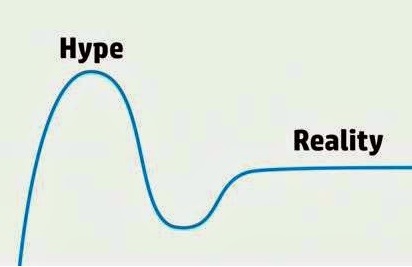 of the moment that generate lots of excitement. The hype around AI has led to the impression that AI is an easy solution to many problems without good understanding of the conditions under which AI provides accurate results. This is far from reality. Reports started to emerge about AI failures and its inability to solve some problems. In many cases the failures are due to unrealistic expectations and the way AI algorithms are applied. Successful AI should satisfy the accuracy requirements of an application.
of the moment that generate lots of excitement. The hype around AI has led to the impression that AI is an easy solution to many problems without good understanding of the conditions under which AI provides accurate results. This is far from reality. Reports started to emerge about AI failures and its inability to solve some problems. In many cases the failures are due to unrealistic expectations and the way AI algorithms are applied. Successful AI should satisfy the accuracy requirements of an application.AI Accuracy
AI accuracy requirements differ for different applications. In the successful sentiment analysis for
 marketing and customer service, the accuracy is only about 68%. In semiconductor defect detection, to ensure high productivity, or to use semiconductor terminology high yield, accuracy is about 95%. The cost of a drug development can run into billions of dollars. To mitigate the risk of failure the accuracy of AI for drug discovery should be greater than 90%. High accuracy leads to precise relationships between drugs, targets, and diseases. Lack of accuracy is one of the reasons why a well-publicized AI product failed to provide solutions to cancer treatment.
marketing and customer service, the accuracy is only about 68%. In semiconductor defect detection, to ensure high productivity, or to use semiconductor terminology high yield, accuracy is about 95%. The cost of a drug development can run into billions of dollars. To mitigate the risk of failure the accuracy of AI for drug discovery should be greater than 90%. High accuracy leads to precise relationships between drugs, targets, and diseases. Lack of accuracy is one of the reasons why a well-publicized AI product failed to provide solutions to cancer treatment.AI Accuracy Begins And Ends With Data
The casual and cavalier approach of feeding any data to an AI algorithm, expecting accurate results is futile. AI accuracy depends on data accuracy, consistency and completeness. Because of the complexity of biomedical data, its ambiguity and entanglement, it is imperative to cleanse and remove irrelevant data prior to feeding the data to an AI algorithm. Iteru developed powerful preprocessing algorithms to cleanse the data and select the data based on the objective of analysis. Concerning completeness, unlike some existing products, Iteru processes all content, not just abstracts.
Biomedical Data Complexity
The complexity of biomedical data is due to the following:
- Interconnection of different aspects of biology: This includes multiple correlated disciplines of genes, proteins, signaling, metabolism, biomarkers etc.
- Entanglement and ambiguities: multiple biological entities are interconnected such that one entity affects hundreds other entities. When searching for drugs, the interactions between the entities could produce unintended results.
- Unknown biological processes: Many biological processes are unknown. Sometimes researchers do not know what to look for when trying to resolve a biological problem.
- Multiple gene/protein names: Some proteins and genes have more than 10 names. Moreover, there are hundreds of thousands of proteins and genes.
There are complex interactions between genes, proteins and molecules inside and outside the cells. The ability to extract patterns related to the interconnections helps researchers to understand the conditions that that drive the initiation or progression of a disease. This may uncover molecular components that leads to drug discovery and diagnostics.
Only pharma domain experts have the knowledge to deal with the complexity of biomedical data. They acquire the knowledge after years of education and training in biomedical sciences. They know the intricacies of the data, how it is generated, the highly specialized biological, medical, and biochemical terms and the complex relationship between different data sets.
Understanding Biomedical Data IS Crucial For Feature Selection
To ensure high AI accuracy it is important to adopt good preprocessing methods and select data based on the objective of analysis. To do this requires good understanding of the data.  Unfortunately, only pharma domain experts understand biomedical data. Most important, they know the processes that lead to disease, drug target identification, protein-protein interactions, DNA-protein interactions and side effects. They know the data required to achieve their objective of analysis and they are the best judge to the viability of the results. If the results of analysis are not satisfactory, they can experiment with different data sets.
Unfortunately, only pharma domain experts understand biomedical data. Most important, they know the processes that lead to disease, drug target identification, protein-protein interactions, DNA-protein interactions and side effects. They know the data required to achieve their objective of analysis and they are the best judge to the viability of the results. If the results of analysis are not satisfactory, they can experiment with different data sets.
Trying to transfer knowledge from a pharma expert to a data scientist to enable them to perform data analysis for drug discovery is extremely difficult, bearing in mind the rapid evolution and the ever-changing pharma domain knowledge. Based on this, the best solution is to empower pharma domain to perform data extraction and preprocessing. Iteru attained this by providing self-service tools.
Existing Algorithms for Feature Selection
The large feature space due to the diverse biological objects and their complex interconnections  poses a serious problem to feature extraction algorithms. There are reports about feature extraction for certain biomedical applications, for instance ensemble feature selection techniques in in the microarray and mass spectrometry domains. However, there is no feature extractor for text and literature that satisfies the high accuracy requirements of AI analysis of biomedical data.
poses a serious problem to feature extraction algorithms. There are reports about feature extraction for certain biomedical applications, for instance ensemble feature selection techniques in in the microarray and mass spectrometry domains. However, there is no feature extractor for text and literature that satisfies the high accuracy requirements of AI analysis of biomedical data.
Concerning biomedical publications, feature extraction is still a formidable challenge. Someone suggested using Random Forest. However Random Forest, like other classifiers depend on the quality and quantity of data. For simple data it can attain 90% accuracy. For complex data like biomedical data one ends up with 25% – 40% accuracy.
Iteru’s Approach To Feature Extraction
Iteru is motivated by its deep conviction that pharma domain experts are the only ones that can select the features based on their objective of analysis. During the course of their research they may decide to include or exclude certain data and modify the extracted features.
To empower domain experts to perform data mining and feature extraction, Iteru provides the following self-service tools:
- Powerful data cleansing algorithms: Biomedical data is very messy. Iteru sampled some documents and found that irrelevant data constitutes at least 35% of the content. Iteru removes irrelevant data.

- Algorithms to perform data mining based on the objective of analysis. For instance, if the objective of analysis is breast cancer, data extraction will be limited to publications about breast cancer. The same is done if the objective of analysis is biomarkers related to cancer immunotherapy, genes, proteins, etc. Moreover, Iteru allows the domain expert to interrogate the data to gain more understanding about its inter-dependencies.
Iteru’s AI algorithms
Following feature extraction an important element of accurate AI is the selection of appropriate algorithms and the tuning of the algorithm. Iteru provides self-service AI algorithms to be used by the domain experts. They can tune the AI parameters so as to obtain optimum results. The best judge for the accuracy of analysis are the domain experts. They are the only ones who can find the best patterns representative of cancer types, treatment, oncogenes, kinases, receptors and markers and other diseases.